
Thématique
Pipeline d’intégration, de nettoyage et de validation de données.
Technologies
- Python (librairies Numpy, Pandas, Matplotlib, Seaborn, Click)
Description
Une base de données relationnelle de type « flocon de neige » a été modélisée à partir de fichiers de type et d’origine multiples (enregistreurs automatiques, mesures manuelles, fichiers au formats variés - .csv, .txt, tableur, etc.). Grâce aux fonctionnalités Python, ces données ont été uniformisées et “nettoyées” tout en respectant les bonnes pratiques statistiques (par exemple, pas de “cherry-picking”, ni de “data dredging”, etc. - cf. Data Fallacies to avoid).
En particulier, les trois étapes suivantes sont importantes dans tout projet de « Data Science » (ou Science des données) :
Typage des variables (category, integers/floats, strings, booleans, dates). Très important, en particulier, pour diminuer l’utilisation de la mémoire vive d’un ordinateur ou serveur
Remplacement (ou imputation) des valeurs manquantes (Figure 1). C’est une étape importante qui permet de préserver la puissance statistique d’un jeux de données
Avant imputation Après imputation 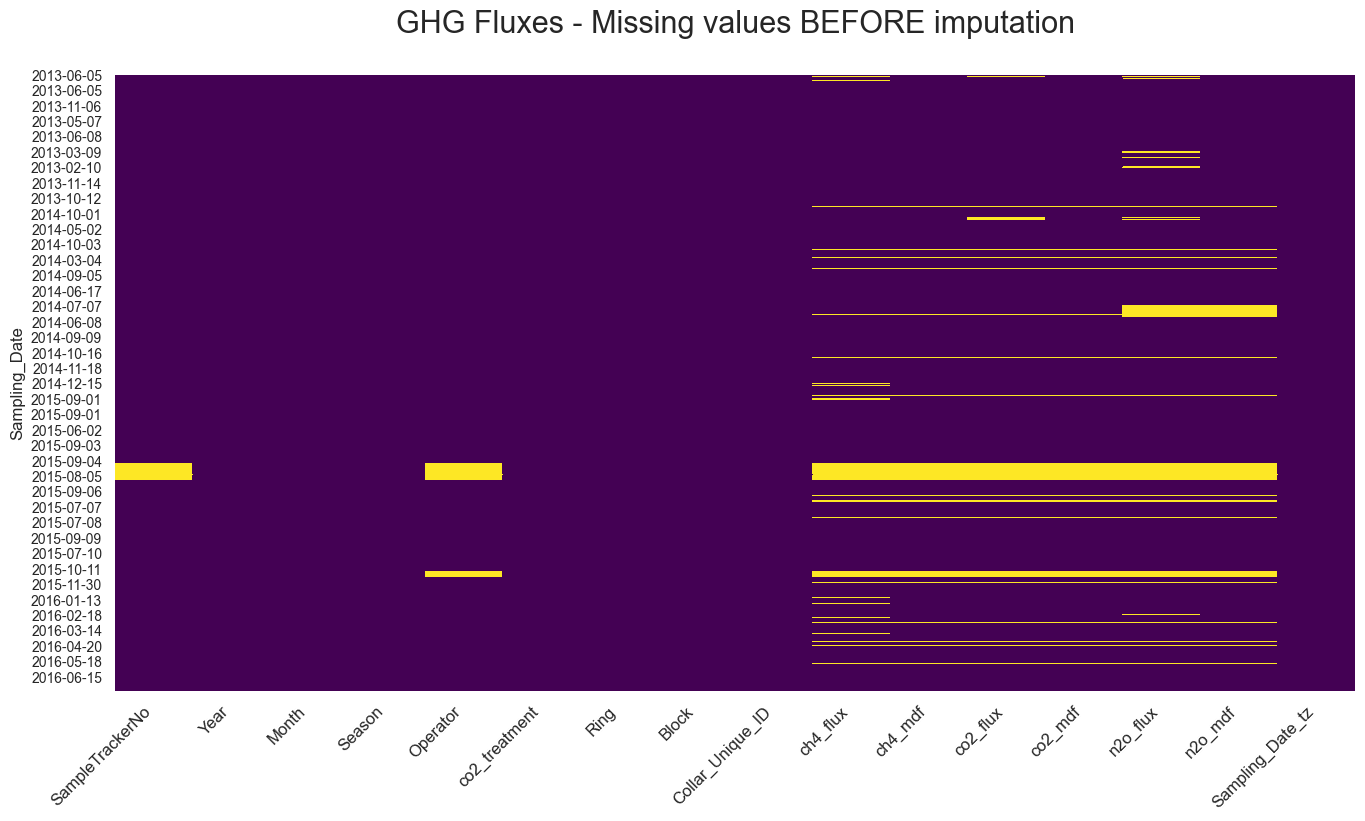
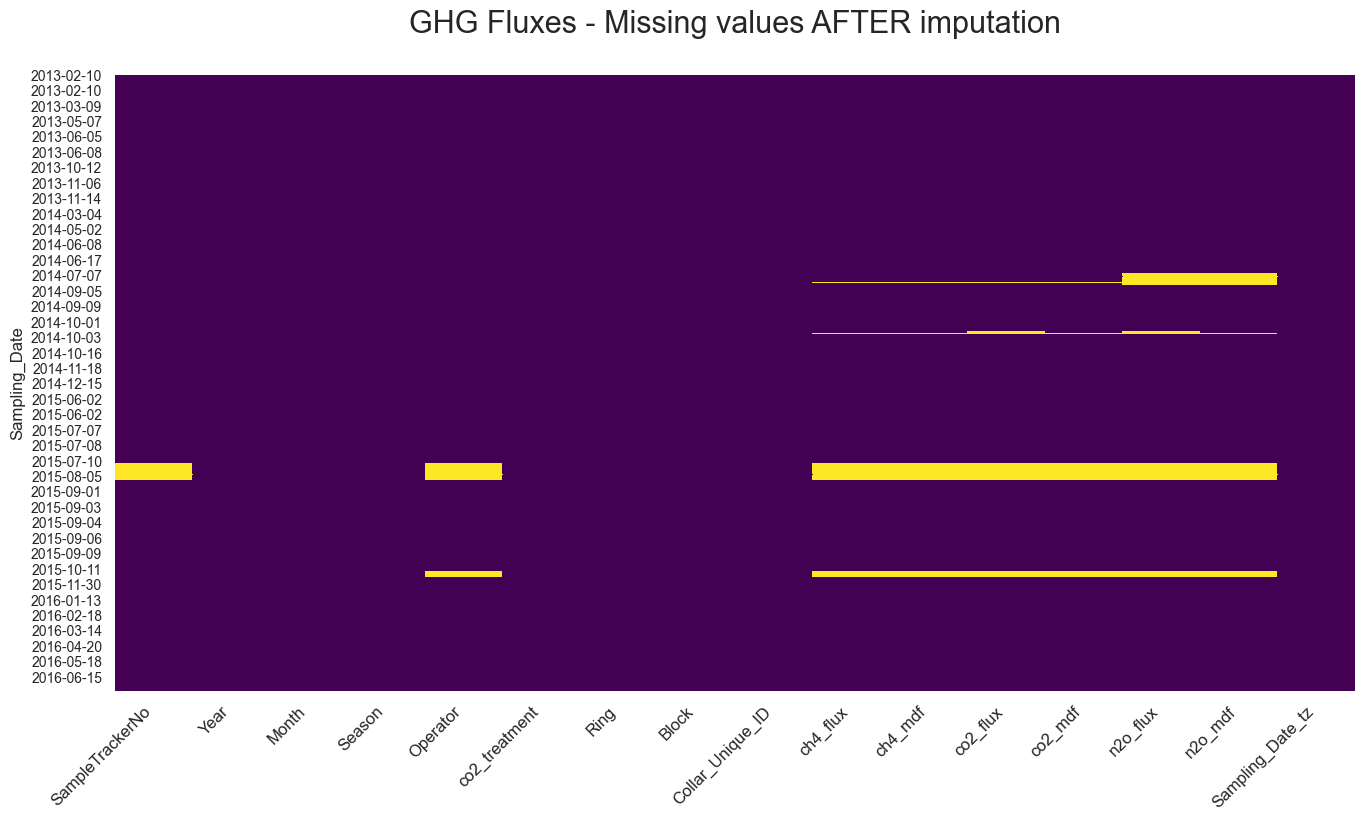
Figure 1: Le remplacement (ou imputation) de valeurs manquantes par approche mathématique. Ici, quand la valeur d’une mesure répliquée (sept (7) réplications en général) était manquante (panneau gauche), elle a été remplacée par la valeur “moyenne” des autres échantillons répliqués. Les valeurs manquantes restantes (panneau droit) représentent des données non-répliquées qui peuvent être imputées en utilisant des approches de « Machine Learning » (ou apprentissage automatique) plus puissantes (non détaillé ici).
Transformation des variables pour obtenir une distribution dite « normale » (Figure 2). Le but est donc de diminuer le nombre de valeurs « extrêmes, c’est-à-dire des valeurs très éloignées de la valeur moyenne.
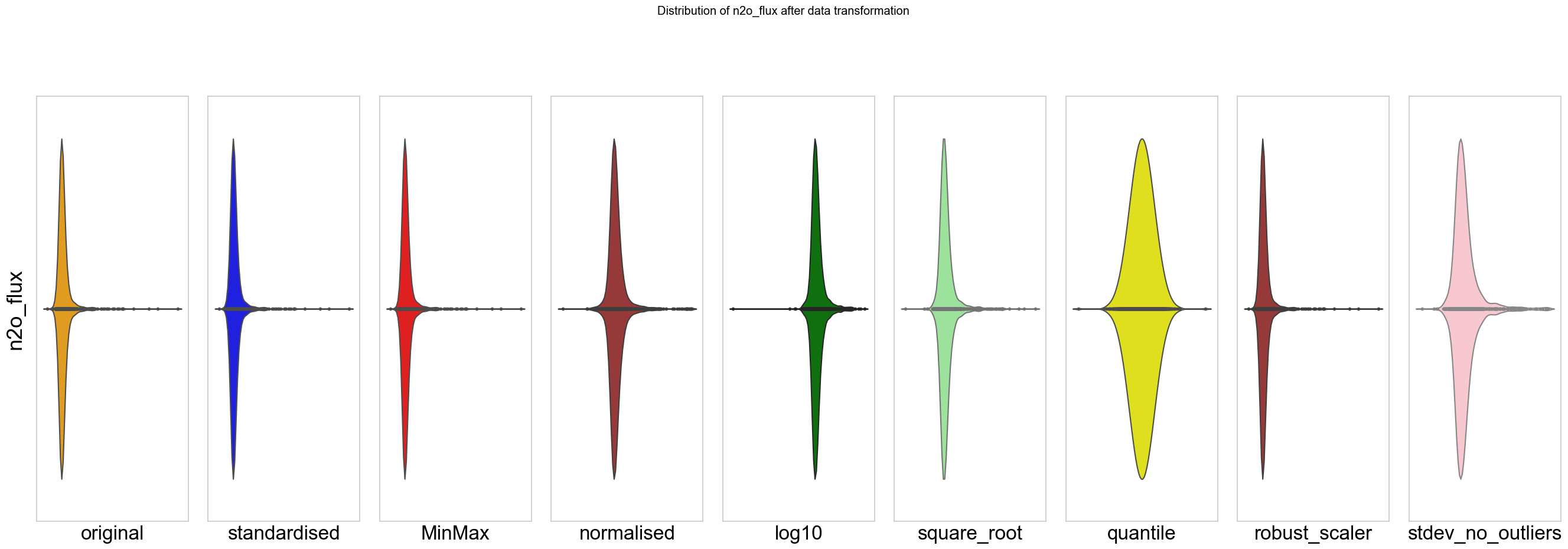
Figure 2: Transformation mathématique des émissions d’oxyde nitreux (N2O). Les différents « violin plots » représentent les diverses transformations des données brutes pour rechercher une « distribution normale » (par exemple, transformation standardisée, transformation en racine carrée, etc.). Le but est d’approcher une distribution symétrique et donc d’éviter des queues (gauches ou droites).
De manière plus générale, il s’agit de préparer les jeux de données pour les étapes d’analyses statistiques et de modélisation (« machine learning »).
[Credit for the header picture] Photo by Quinten de Graaf on Unsplash